
Nous sommes partis d'un constat simple : bien que les Large Language Models (LLM) soient extrêmement performants pour la compréhension et la génération de texte, ils montrent des faiblesses lorsqu'il s'agit de tâches nécessitant des connaissances spécifiques ou des capacités multimodales, comme le traitement d'images. Pourtant, certains modèles de machine learning, ou plus simplement des fonctions spécifiques, peuvent exceller dans ces tâches.
Objectif du Stage :
L'objectif était donc simple : durant ce stage, un Proof of Concept (POC) a été développé pour démontrer l'efficacité d'une architecture hybride basée sur un Large Language Model (LLM) appuyé par des plugins spécialisés.
Architecture Mise en Place :
Voici quelques éléments pour mieux comprendre l'architecture développée :
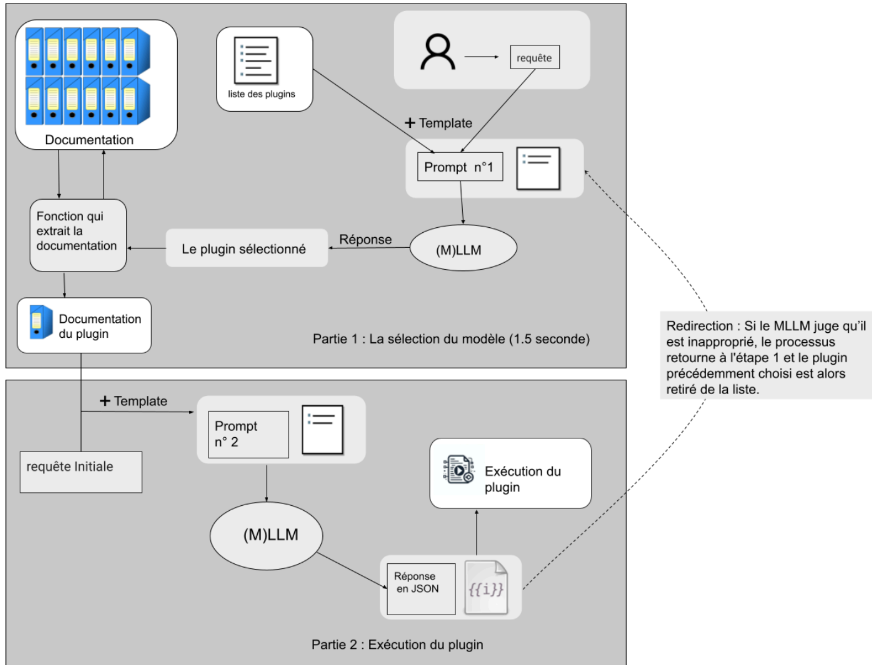
- Formation du premier prompt à partir de la liste de plugins, de la requête et du template
- Sélection du plugin par le (M)LLM
- Si le plugin demande des paramètres :
- Récupération de la documentation du plugin
- Formation du deuxième prompt à partir de la documentation, de la requête et du template
- Génération du JSON
- Optionnel : Redirection si le plugin sélectionné est jugé inapproprié par le (M)LLM
- Exécution du plugin
Évaluation des Performances :
Nous avons créé notre propre benchmark pour évaluer l'efficacité de la sélection des plugins et la génération des paramètres. Les résultats obtenus montrent des précisions très satisfaisantes avec un score de 98,9 % de réussite pour la sélection du plugin et de 93,4 % pour la génération des paramètres.
Développement des Plugins :
Des plugins ont été développés pour illustrer des cas d'usage importants dans un contexte industriel. Chaque plugin a été conçu pour répondre à des besoins spécifiques et optimiser le traitement des données dans diverses situations.
RAG Plugin :
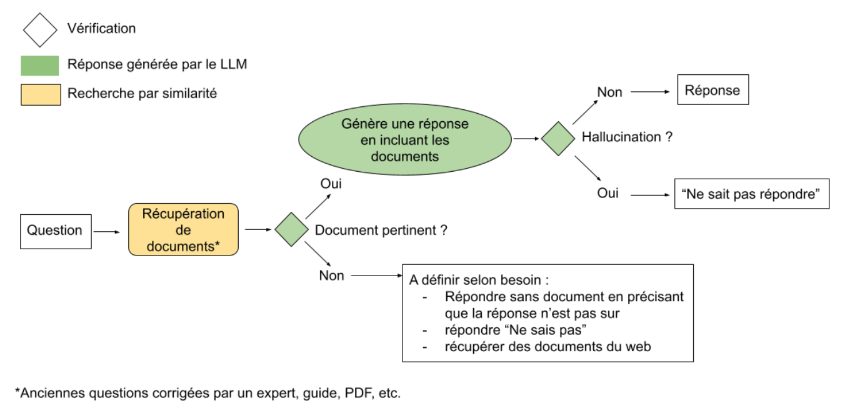
Le plugin RAG (Retrieval-Augmented Generation) a été développé et optimisé pour répondre à des questions dans des domaines spécifiques où une base de connaissances est disponible. Ce plugin permet de fournir des réponses précises en s'appuyant sur cette base de connaissances tout en citant les sources utilisées. Il est particulièrement efficace pour des applications où l'exactitude et la traçabilité des informations sont cruciales.
Présentation d'OWLv2
OWLv2 est un modèle avancé de détection d'objets utilisant un vocabulaire ouvert, capable de reconnaître des objets qu'il n'a pas explicitement appris à détecter lors de son entraînement. Grâce à une méthode d'auto-formation (self-training) et à l'exploitation de données massives provenant d'Internet, OWLv2 élargit considérablement sa base de données d'entraînement, atteignant une grande précision même sur des objets inconnus via la détection zéro-shot. Cette technologie repose sur des embeddings sémantiques qui permettent de transférer les connaissances d'objets connus à des objets inconnus.
Cas d'usage :
- Comptage en zone dense : OWLv2 peut être utilisé pour compter avec précision des objets dans des environnements denses, comme des foules ou des ensembles de produits en magasin, en exploitant sa capacité à identifier un grand nombre d'éléments différents.
- Identification zéro-shot avec un text query : En fournissant au modèle une image et une liste de termes (text query), OWLv2 est capable d'identifier des objets qu'il n'a jamais rencontrés pendant sa phase d'apprentissage, démontrant ainsi sa puissance dans des scénarios où l'inventaire des objets est constamment en évolution.

Comptage d'objets en zone dense. Résultat lorsqu'on demande d'identifier les "block".

Identification d'objets. Résultat lorsqu'on demande d'identifier “hat”, “book”, “sunglasses”, “camera”.
Plugin de Classification :
Le plugin de Classification a été développé pour effectuer des tâches de catégorisation automatique en utilisant un fine-tuning du modèle de vision YOLOv8. Ce plugin est essentiel pour des applications telles que la classification d'images de produits défectueux ou normaux sur une chaîne de distribution, par exemple.

Exemple d'application du plugin de Classification : détection la présence et l'absence de casque
Plugin SQL: DrugReviewSQLSearch
DrugReviewSQLSearch est un plugin conçu pour interagir avec une base de données contenant des informations sur les médicaments, associées à une maladie, un commentaire, une note, et une date. Ce plugin sert à interroger la base de données afin de récupérer des informations pertinentes, telles que :
- Liste des médicaments pour une maladie spécifique : Identifier les médicaments les plus couramment prescrits pour une certaine condition médicale.
- Avis des patients : Accéder aux commentaires des patients sur l'efficacité et les effets secondaires des médicaments.
- Évaluation des médicaments : Obtenir les notes pour évaluer l'efficacité du médicament.
- Analyse temporelle : Examiner les avis sur une période spécifique pour observer des tendances ou des changements.